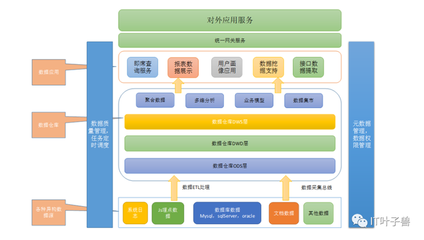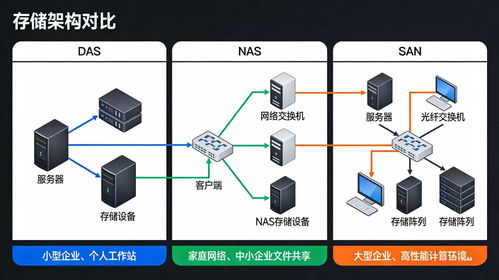
在林子雨编著的《大数据技术原理与应用》第八章中,作者深入探讨了Hadoop作为大数据处理与存储的核心平台。Hadoop不仅是一个简单的工具,而是一个完整的生态系统,涵盖了数据存储、处理、分析和应用的多个层面。本章从Hadoop的基本概念出发,逐步深入到其存储与数据处理服务的关键机制。
一、Hadoop核心概念回顾
Hadoop由Apache基金会开发,是一个开源的分布式计算框架,旨在处理海量数据。其核心设计理念包括分布式存储(HDFS)和分布式计算(MapReduce)。HDFS提供了高容错性的数据存储,能够将大文件分割成多个块并分布在集群的节点上;MapReduce则是一种编程模型,用于并行处理大规模数据集。YARN(Yet Another Resource Negotiator)作为资源管理器,负责集群资源的调度与管理,使Hadoop能够支持多种计算框架(如Spark、Flink等)。
二、数据存储服务:HDFS的深入解析
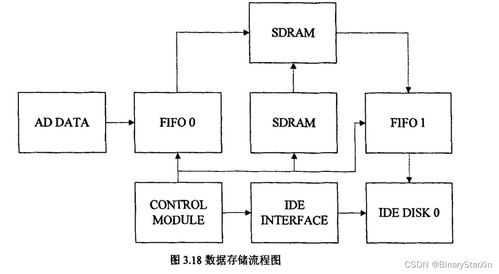
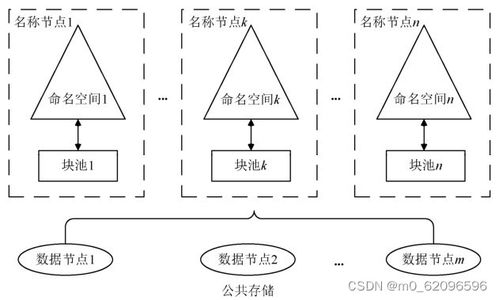
HDFS是Hadoop的存储基石,其架构包括NameNode和DataNode。NameNode作为主节点,管理文件系统的元数据(如文件目录结构和块位置),而DataNode作为从节点,负责实际数据的存储。HDFS通过数据冗余(默认复制三份)确保高可用性,即使节点故障也能保证数据不丢失。HDFS支持流式数据访问,适合一次写入、多次读取的场景,例如日志分析或数据仓库应用。本章还探讨了HDFS的优化策略,如数据块大小调整(默认128MB)和机架感知策略,以减少网络带宽消耗并提升性能。
三、数据处理服务:MapReduce与YARN的协同工作
MapReduce是Hadoop的数据处理引擎,其工作流程分为Map和Reduce两个阶段。在Map阶段,输入数据被分割成键值对并进行初步处理;在Reduce阶段,中间结果被聚合以生成最终输出。YARN的出现使Hadoop从单一的MapReduce框架演变为一个多任务平台,它通过ResourceManager和NodeManager管理集群资源,允许用户运行不同类型的应用程序。这种分离提高了资源利用率和系统灵活性,使得Hadoop能够适应实时处理、机器学习等多样化需求。
四、分析与应用:Hadoop生态系统的扩展
Hadoop生态系统不仅限于存储和处理,还包括多种工具以支持数据分析和应用。例如,Hive提供SQL-like查询功能,简化了大数据分析;HBase作为分布式数据库,支持实时读写操作;Pig则提供高级脚本语言,用于复杂的数据流处理。在实际应用中,Hadoop被广泛应用于金融风控、医疗数据分析、电商推荐系统等领域。通过结合这些工具,企业能够构建端到端的大数据解决方案,从原始数据中提取有价值的信息,驱动业务决策和创新。
五、挑战与未来展望
尽管Hadoop在大数据领域占据重要地位,但也面临一些挑战,如复杂的管理、实时性不足以及安全性的提升需求。随着云计算和边缘计算的发展,Hadoop可能会与容器化技术(如Docker和Kubernetes)更紧密地结合,实现更灵活的部署。开源社区的持续创新将推动Hadoop生态系统不断进化,以应对日益增长的数据处理需求。
第八章的“Hadoop再探讨”强调了其作为数据处理和存储服务的核心角色,并展示了如何通过深入理解其原理与应用,构建高效、可靠的大数据平台。对于学习者和从业者而言,掌握Hadoop不仅是技术基础,更是解锁大数据价值的关键一步。