引言:云原生时代的基石
在数字化转型浪潮中,应用开发与部署模式正经历深刻变革。容器技术,特别是以Docker为代表的容器化方案,通过将应用及其依赖封装成轻量级、可移植的单元,解决了“在我机器上能运行”的经典难题。当企业试图在生产环境中大规模部署和管理成百上千的容器时,挑战接踵而至:如何调度?如何扩展?如何确保高可用与自愈?此时,容器编排 应运而生,而Kubernetes 无疑是这个领域的王者与事实标准。
一、Kubernetes:容器编排的领航者
Kubernetes(常简称为K8s)是一个开源的容器编排平台,起源于Google内部的Borg系统。它提供了一个强大的框架,用于自动化部署、扩展和管理容器化应用。其核心价值在于:
- 声明式配置与自动化:用户通过YAML或JSON文件声明应用的期望状态(如运行3个副本),K8s的控制平面会持续工作,确保实际状态与期望状态一致,自动处理节点故障、容器重启等。
- 服务发现与负载均衡:K8s可以自动为容器组(Pod)分配IP地址和DNS名称,并通过Service等抽象实现流量的负载均衡,使微服务间的通信变得简单可靠。
- 弹性伸缩:支持根据CPU、内存使用率或自定义指标进行水平自动伸缩,从容应对流量高峰。
- 自我修复:自动重启故障容器、重新调度失效节点上的容器、替换不健康的容器,保障应用持续可用。
二、Kubernetes在数据处理与存储服务中的关键角色
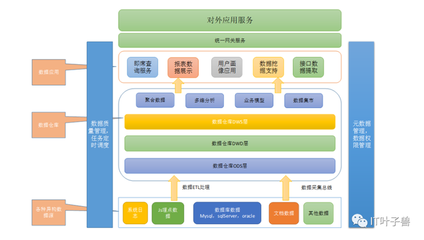
数据处理与存储是现代应用的“心脏”,其需求包括持久化、高性能、可扩展性和高可用。Kubernetes通过一系列原生概念和扩展机制,为这些需求提供了优雅的解决方案。
1. 数据持久化:Volume与PersistentVolume
容器本身是临时的,其文件系统生命周期与容器相同。Kubernetes通过 Volume(卷) 抽象解决了数据持久化问题。
- 基础Volume:支持多种类型,如hostPath(节点本地目录)、NFS、云存储等,允许容器访问外部存储。
- PersistentVolume (PV) / PersistentVolumeClaim (PVC):这是更高级的存储管理模型。管理员预先配置存储资源池(PV),用户通过PVC声明存储需求(如大小、访问模式)。K8s自动将PVC与合适的PV绑定,实现了存储的“按需供给”,与应用部署解耦。这对于数据库、文件服务器等有状态应用至关重要。
2. 有状态应用编排:StatefulSet
Deployment适用于无状态应用,但对于MySQL、Kafka、Elasticsearch等有状态服务,需要稳定的网络标识、有序的部署/扩展和持久的存储。StatefulSet 正是为此设计:
- 稳定的Pod标识:每个Pod拥有一个永久的、按序的标识符(如
kafka-0,kafka-1),即使重启或重新调度,其主机名和存储卷保持不变。 - 有序部署与管理:Pod按顺序创建、扩展或删除,确保集群化服务(如主从数据库)的启动顺序和稳定性。
- 与PVC的强关联:每个Pod实例可以拥有自己专用的PVC,确保数据与实例一一对应,避免混乱。
3. 数据处理工作流与批处理:Job与CronJob
数据处理不仅限于长期运行的服务,还包括定时任务和批处理作业。Kubernetes提供了:
- Job:创建一个或多个Pod,并确保指定数量的Pod成功终止。用于运行一次性任务,如数据迁移、报表生成。
- CronJob:基于时间表(Cron表达式)周期性运行Job,完美支持数据备份、定期ETL(提取、转换、加载)等场景。
4. 与生态系统的集成
Kubernetes的强大还体现在其蓬勃发展的生态系统上,特别是在数据处理与存储领域:
- 云原生存储方案:如Rook(提供Ceph、EdgeFS等存储系统的K8s原生编排)、Longhorn(轻量级、易用的分布式块存储)、OpenEBS(容器原生存储)。
- 大数据与流处理框架:Apache Spark、Flink、Kafka等主流框架都提供了Kubernetes原生支持或Operator,可以直接在K8s集群上运行,享受统一的资源调度和管理便利。
- 数据库Operator:通过Operator模式(一种K8s的扩展机制),可以像管理原生K8s资源一样管理复杂的有状态应用。例如,PostgreSQL的Crunchy Data Operator、MySQL的Oracle Operator,它们自动化了数据库的部署、备份、恢复、升级等运维操作。
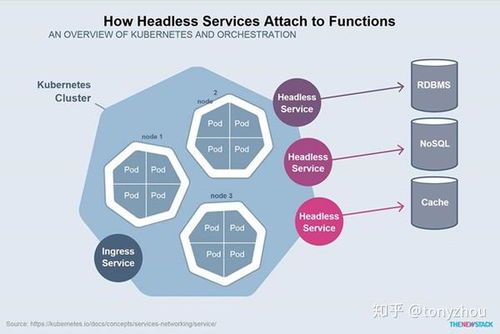
三、总体架构与工作流程
一个典型的在Kubernetes上运行数据处理服务的工作流程如下:
- 定义存储:管理员创建存储类(StorageClass),定义动态供给的存储类型。用户通过PVC申请持久化存储。
- 部署有状态服务:使用StatefulSet定义数据库或消息队列(如MySQL集群),每个Pod实例自动关联一个独立的PVC。
- 部署数据处理应用:使用Deployment部署微服务或无状态数据处理应用(如API服务、转换服务)。它们通过K8s Service访问有状态服务。
- 运行批处理任务:使用Job或CronJob运行数据分析脚本或定时任务,任务可以挂载PVC或ConfigMap(用于配置)来读取和写入数据。
- 监控与伸缩:利用Horizontal Pod Autoscaler根据数据处理负载自动调整应用实例数,并通过Prometheus等监控工具观察整个数据流水线的健康状况。
###
Kubernetes不仅是一个容器编排器,更是一个强大的分布式系统平台。它将计算、网络和存储的抽象提升到一个新的高度,使得构建和管理复杂、弹性的数据处理与存储服务变得前所未有的标准化和自动化。通过将存储生命周期与容器生命周期解耦,并通过StatefulSet、Operator等模式为有状态应用提供一流支持,Kubernetes正成为云原生时代数据基础设施的坚实底座。拥抱Kubernetes,意味着拥抱更高效、更可靠、更敏捷的数据驱动未来。