在当今数据驱动的时代,如何高效、可靠地存储和访问海量结构化数据,是许多大型科技公司面临的核心挑战之一。Google 内部开发的 Bigtable 系统,正是为应对这一挑战而诞生的一种高性能、可扩展的分布式结构化数据存储系统。它并非传统的关系型数据库,而是一个稀疏的、分布式的、持久化的多维排序映射表,专为处理 PB 级别的大规模数据而设计,并深刻影响了后来如 Apache HBase、Cassandra 等众多开源分布式数据库的发展。
一、核心数据模型:一个多维度的映射表
Bigtable 的数据模型简洁而强大。它将所有数据组织成一张巨大的表。这张表的行键(Row Key)是任意的字符串,对数据的读取至关重要,因为数据按行键的字典顺序排列。每一行数据又由多个列族(Column Family)组成,列族是访问控制的基本单位,需要在表创建时预先定义。每个列族下包含任意数量的列限定符(Column Qualifier),从而在列族内形成了动态的、稀疏的列空间。表中的每个数据单元格(Cell)由行键、列族、列限定符唯一确定,并包含一个时间戳版本,从而实现数据的多版本管理。这种 (row:string, column:string, timestamp:int64) → string 的映射模型,提供了极大的灵活性,既能模拟简单的键值存储,也能通过精心设计行键和列来模拟更复杂的数据结构。
二、系统架构与关键组件
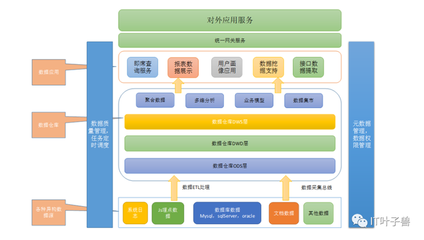
Bigtable 的架构设计充分体现了分布式系统的核心思想:分而治之与冗余备份。其核心组件包括:
- Bigtable 客户端库:应用程序通过客户端库访问 Bigtable。客户端库不直接与底层存储通信,而是与 Tablet Server 交互,并缓存了重要的元数据位置信息。
- Master 服务器:承担管理员的角色,主要负责将 Tablet(数据表被按行范围分割后的连续片段)分配给 Tablet Server,监测 Tablet Server 的增删与负载均衡,以及处理表模式变更(如创建列族)等元数据操作。值得注意的是,Master 并不参与实际的数据读写流程,这避免了其成为系统瓶颈。
- Tablet Server:系统的工作主力,每个 Tablet Server 管理一组 Tablet(通常为数十至上千个)。它直接处理对其管理的 Tablet 的读写请求,并在 Tablet 规模过大时负责对其进行分割。数据在内存和磁盘间流动,持久化层依赖于 Google 的分布式文件系统 GFS(现为 Colossus)。
- Chubby 服务:一个高可用的分布式锁服务,在 Bigtable 中扮演着至关重要的角色。它用于确保 Master 选举的唯一性、存储 Bigtable 数据的引导位置(即 Root Tablet 的位置)、存储 Tablet Server 的注册信息以及访问控制列表。Chubby 的可用性直接关系到 Bigtable 集群的可用性。
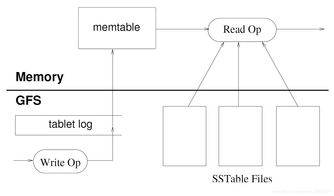
数据的持久化存储采用“日志-内存表-磁盘文件”的多层结构。写入操作首先被提交到提交日志(存储在GFS),然后插入到内存中的有序结构(MemTable)中。当 MemTable 大小达到阈值,它会被冻结并转换为不可变的 SSTable(Sorted String Table)格式文件写入GFS。SSTable 是持久化的、内部有序的不可变数据文件。读取操作需要合并 MemTable 和多个 SSTable 中的数据。定期的压缩(Compaction)过程负责合并多个 SSTable,清理已删除的数据,以优化读取性能和控制存储空间。
三、作为数据处理与存储服务的特性
Bigtable 不仅仅是一个存储系统,它更是一个为上层应用提供高效数据处理能力的基础服务。
- 强大的可扩展性:通过增加 Tablet Server 即可线性地扩展集群的存储容量和吞吐量。表被自动分割成多个 Tablet 分布到众多服务器上,实现了负载的分散。
- 高性能:设计目标之一就是应对高吞吐、低延迟的应用场景。数据模型和存储格式的优化、客户端元数据缓存、以及将 SSTable 加载到本地磁盘(在 GFS 之上)等机制,共同保障了快速的读写访问。
- 高可用性与可靠性:数据通过 GFS 进行多副本存储,保证了数据的持久性。Tablet 可以在 Tablet Server 之间动态迁移,当某个服务器失效时,其管理的 Tablet 会被 Master 迅速重新分配到其他可用服务器上,从而恢复服务。
- 灵活的适用性:尽管数据模型简单,但通过巧妙设计行键(如将反转的域名“com.google.www”作为行键以实现同一域名下网页的连续存储),Bigtable 能够高效支持从网页索引、Google Earth、Google Analytics 到个性化推荐等极其多样化的 Google 内部服务,展示了其作为通用底层存储服务的强大适配能力。
- 与数据处理生态的集成:在 Google 内部,Bigtable 与 MapReduce、Spanner、Flume 等数据处理和计算框架紧密集成,构成了完整的大数据生态系统。数据可以方便地从 Bigtable 导出进行批量分析,分析结果也可以写回 Bigtable 供在线服务低延迟访问。
四、与影响
Bigtable 的成功在于它在简单性与功能性、性能与扩展性之间取得了精妙的平衡。它舍弃了关系型数据库的复杂特性(如跨行事务、复杂的查询语言),换来了在海量数据规模下无与伦比的扩展性和性能。其论文中阐述的设计理念,如基于列族的数据组织、SSTable 存储格式、依赖底层分布式文件系统与锁服务等,已成为构建现代分布式数据库的教科书级范式。
今天,虽然云原生时代出现了更多新的数据库类型,但 Bigtable 及其思想遗产,依然是处理超大规模、强一致性要求的在线结构化数据服务的坚实基石,持续为全球各地的企业级应用提供着强大的数据处理和存储动力。