近日,Apache InLong成功从孵化器毕业,正式成为Apache软件基金会的顶级项目,标志着其在数据流处理领域的成熟与认可。该项目专注于构建高效、可靠的数据处理与存储服务,其核心亮点在于能够支持百万亿级别的数据流处理能力。
一、Apache InLong概述
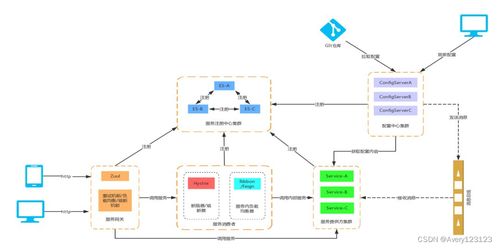
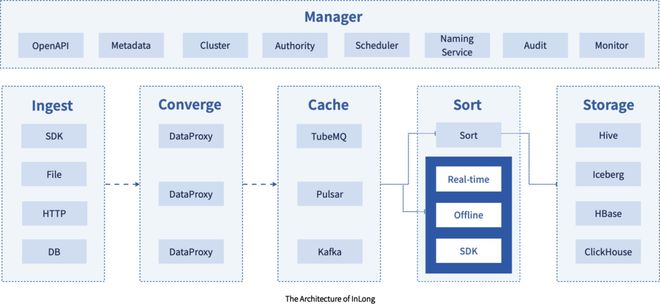
Apache InLong(原名TubeMQ)是一个一站式的数据流接入与处理平台,旨在简化数据采集、聚合、存储和分发的全流程。其设计目标是为大规模数据场景提供低延迟、高吞吐的解决方案,尤其适用于实时数据流处理需求。
二、技术亮点与核心能力
- 百万亿级数据流处理能力:Apache InLong通过分布式架构和优化的消息队列机制,实现了对海量数据的高效处理。它能够轻松应对每日百万亿条数据流的接入与传输,确保数据在复杂网络环境下的稳定流动。这种能力得益于其可扩展的节点设计和负载均衡策略,使得系统在数据量激增时仍能保持高性能。
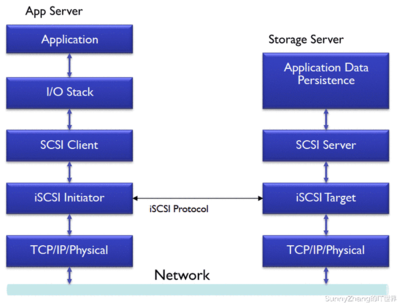
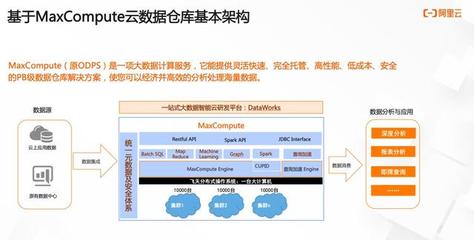
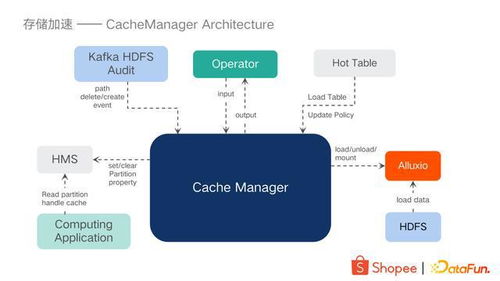
- 数据处理与存储服务集成:InLong提供一体化的数据处理框架,支持多种数据源(如日志、数据库、IoT设备)的实时采集,并通过内置的ETL(提取、转换、加载)功能进行数据清洗和转换。同时,它与主流存储系统(如HDFS、Kafka、ClickHouse)无缝集成,实现数据的快速存储和查询,降低了用户在多系统间切换的复杂性。
- 高可靠性与容错机制:项目采用多副本和数据校验技术,确保数据在传输和存储过程中的完整性与一致性。即使出现节点故障,系统也能自动恢复,避免数据丢失,这对企业级应用至关重要。
- 易用性与生态系统兼容:InLong提供友好的管理界面和API,支持快速部署和监控。它与Apache生态系统中的其他项目(如Flink、Spark)深度整合,助力用户构建端到端的数据管道。
三、应用场景与未来展望
Apache InLong的毕业不仅是对其技术实力的肯定,也为大数据行业带来了新的选择。它广泛应用于金融风控、物联网数据分析、日志监控等场景,帮助企业在海量数据中挖掘价值。未来,随着AI和实时计算需求的增长,InLong有望通过持续优化,进一步降低数据处理门槛,推动数据驱动决策的普及。
Apache InLong作为顶级项目,凭借其百万亿级处理能力和一体化服务,正在成为数据流处理领域的重要基石。用户可通过官方文档和社区资源,快速上手并受益于其强大功能。