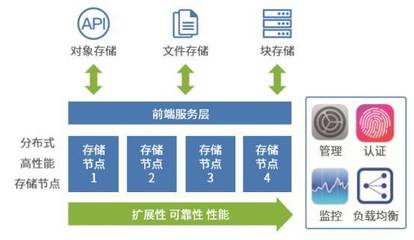
随着大数据与云原生技术的深度融合,企业对于实时、高效、低成本的数据处理与存储需求日益增长。传统的数据仓库架构在面对海量、多源、频繁更新的数据时,常显露出性能瓶颈、管理复杂与存储成本高昂等问题。在此背景下,结合Apache Flink的流批一体处理能力与Apache Iceberg的表格式抽象,并以对象存储(如AWS S3、阿里云OSS、腾讯云COS等)为底层存储,构建现代化数据湖方案,已成为业界实现统一、可扩展、低成本数据处理与存储服务的重要路径。
一、 核心组件:强强联合的技术栈
- Apache Flink:作为流批一体的计算引擎,Flink提供了高吞吐、低延迟的数据处理能力,支持精确一次(Exactly-Once)语义,并能够无缝处理有界(批)和无界(流)数据。其成熟的生态系统和丰富的连接器(Connector)使其成为数据入湖、湖内ETL及数据服务层计算的理想选择。
- Apache Iceberg:作为一种开源的表格式(Table Format),Iceberg在HDFS或对象存储之上提供了一层高效的抽象。它解决了Hive表格式在并发写入、数据更新、模式演进(Schema Evolution)和时间旅行(Time Travel)等方面的诸多痛点。其核心特性包括:
- ACID事务支持:确保多任务并发读写时数据的一致性。
- 隐式分区与分区演进:解耦物理存储与查询逻辑,允许灵活修改分区策略。
- 高性能元数据管理:利用清单文件(Manifest)和快照(Snapshot)机制,实现快速的文件列表和元数据操作,极大提升了查询性能。
- 完整的版本控制:支持时间旅行、回滚和数据血缘追踪。
- 对象存储(Object Storage):作为数据湖的存储基石,对象存储提供了近乎无限的扩展性、极高的持久性(通常99.999999999%)和极具竞争力的成本。其按使用量付费的模式,使得存储海量历史数据的经济性远胜于传统块存储或HDFS。
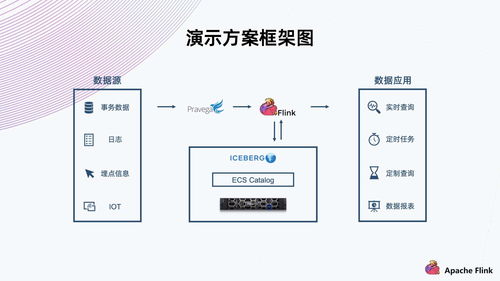
二、 方案架构:数据处理与存储服务的融合
典型的基于Flink-Iceberg-对象存储的数据湖架构通常分为三层:
- 摄入与计算层(Flink):
- 实时摄入:通过Flink SQL或DataStream API,直接从Kafka、MySQL Binlog等数据源消费数据,利用Flink-Iceberg Connector实时写入Iceberg表。
- 批处理与ETL:对已入湖的数据,使用Flink Batch模式进行复杂的清洗、转换、聚合,并将结果写回Iceberg表,供上层分析使用。
- 流式分析:构建实时数仓,直接在数据湖的流式数据上实现实时聚合、关联分析,结果可实时更新到Iceberg表或对外提供服务。
- 表格式与元数据层(Iceberg):
- 该层是架构的“智能大脑”。Iceberg维护着表的结构(Schema)、分区信息、数据文件列表及所有快照历史。所有对数据的读写操作都通过Iceberg的接口进行,由其保证事务性和一致性。元数据本身也存储在对象存储中,实现了存算分离。
- 持久化存储层(对象存储):
- 作为所有数据文件(Parquet、ORC、Avro格式)和Iceberg元数据文件的最终存放地。对象存储的廉价、可靠和无限扩展特性,使得数据湖可以容纳从原始细节数据到高度聚合数据的全量数据,并长期保存。
三、 关键优势:构建一体化数据服务
- 统一的批流存储与服务:Flink处理后的数据,无论是实时流还是历史批数据,都统一写入Iceberg表。数据分析师和数据科学家可以通过同一张Iceberg表,使用Trino/Presto、Spark、Flink自身或Hive等引擎,进行即席查询、批处理报告或机器学习训练,真正实现“一份存储,多种计算”。
- 卓越的存储经济性与扩展性:对象存储的成本效益极高,尤其适合存储冷温数据。数据湖的规模可以随业务增长平滑扩展,无需预先规划和昂贵的硬件扩容。
- 强大的数据治理与可靠性:Iceberg的ACID事务保障了数据质量,时间旅行和版本回溯功能便于数据审计与故障恢复。其精细化的元数据管理也简化了数据生命周期管理(如过期数据清理)。
- 解耦的灵活架构:存算分离架构允许计算资源(Flink集群、查询引擎集群)根据负载独立弹性伸缩,与存储层互不影响,提升了资源利用率和系统整体弹性。
四、 实践建议与挑战
- 实践建议:
- 小文件治理:流式持续写入易产生小文件,需合理配置Flink Checkpoint间隔和Iceberg的提交策略,或定期使用Flink/Spark作业进行小文件合并(Compaction)。
- 元数据优化:定期执行Iceberg的
expire<em>snapshots和remove</em>orphan_files操作,清理过期元数据和数据文件,控制成本。
- 查询加速:对于热点数据,可结合Alluxio等缓存层提升查询性能;合理设计Iceberg表的分区与排序策略,利用数据剪枝(Data Skipping)提升查询效率。
- 潜在挑战:
- 对象存储的最终一致性模型可能带来短暂的读取延迟(但Iceberg通过原子操作在很大程度上规避了此问题)。
- 跨地域访问对象存储可能存在网络延迟和成本,需合理规划存储区域与计算集群的位置。
- 需要一支熟悉Flink、Iceberg和云原生基础设施的团队进行运维和调优。
结论:
以Apache Flink为动力引擎,Apache Iceberg为组织规范,对象存储为坚实基座,所构建的现代数据湖方案,为企业提供了兼顾实时性与经济性、统一灵活且易于治理的数据处理与存储服务平台。它不仅是技术栈的升级,更是面向未来数据驱动业务的数据架构范式转变,能够有效支撑从实时分析、交互查询到机器学习的全场景数据应用,释放数据资产的深层价值。